
这篇是用来记命令的,教学视频是看黑马程序员的
开始
注意:得先安装和配置好MySQL,再Windows搜索里找到MySQL 8.0 Command Line Client这个终端程序。打开进入终端,提示信息会让你输入密码(就是你配置MySQL用户root的那个密码)一般都是:123456。
显示当前所有数据库
1 | show databases; |
效果:
1 | +--------------------+ |
查询当前数据库
1 | select database(); |
效果:
当前还未进到任何数据库中所以是NULL(空)。
1 | +------------+ |
创建一个名为test1的数据库
1 | create database test1; |
效果:
1 | Query OK, 1 row affected (0.01 sec) |
出现以上提示,说明是创建成功的
Navicat-数据库管理工具
如果我们一直在终端的环境下敲打命令,查看结果就是一片黑乎乎的背景和一堆的白色字母,是不是单调很多, 接下来我们就来使用一款可视化工具————Navicat。
Q: 为什么说要用Navicat啊?
站长:我也不知道哇,只不过很多企业都用这个。
Q: JetBrains全家桶里也有DataGrip(数据库管理工具)
站长: DataGrip我也用过,但里面都是图形化界面,我想初学者还是从敲命令一步一步来吧。
1、 打开浏览器,搜索Navicat官网,在最上面导航栏那处找到-产品-这个选项,点击,在那么多的Navicat版本里我们一直往下划,找到Navicat Premium Lite这一介绍,对就是这里,然后选择这里的Navicat下载。
2、 安装包下好,安装好,之后还会让你注册一个账号,不会太久的。全部弄完来到Navicat的页面–>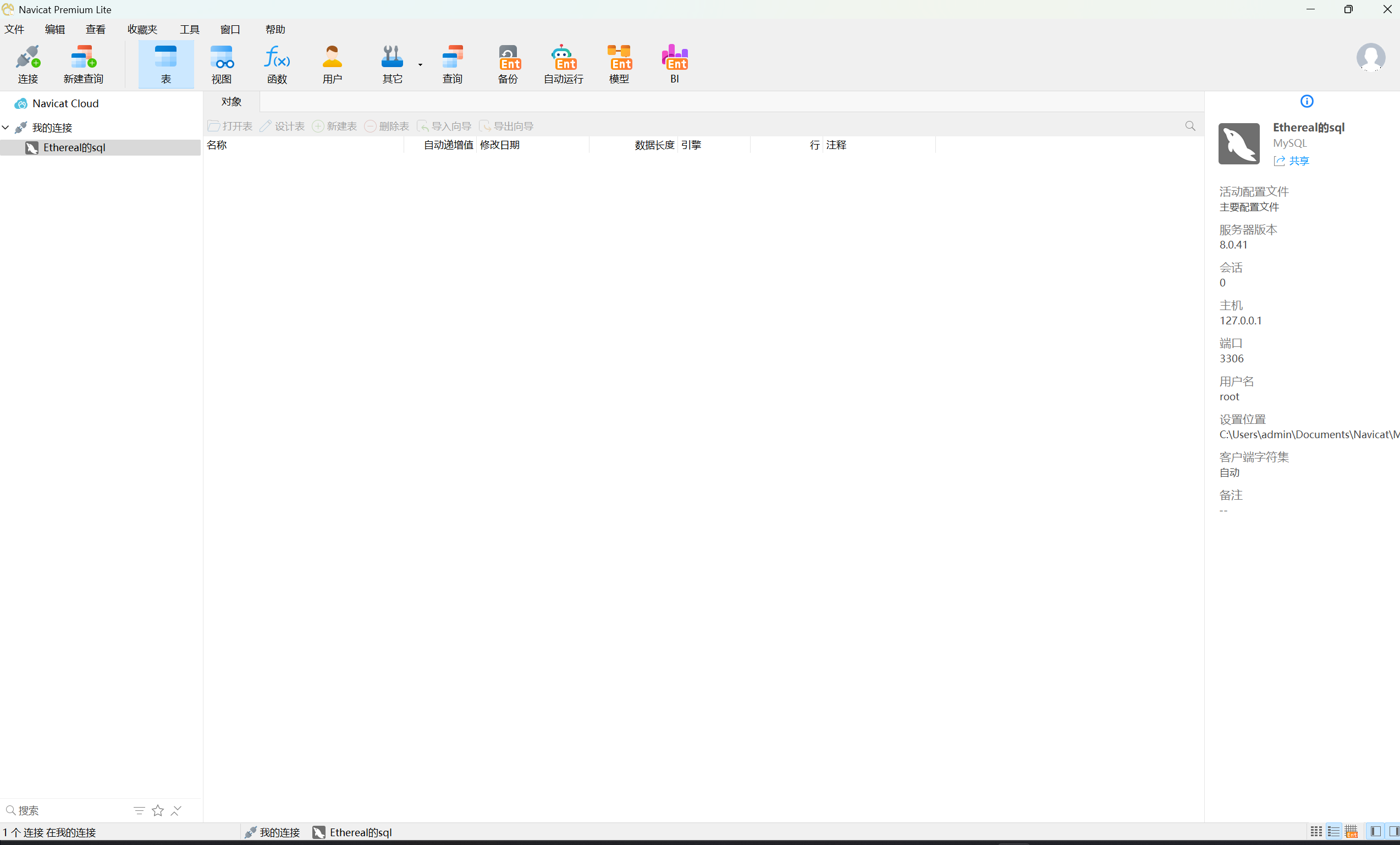
这里有一个我先前就弄好的,所以我们重新连接之前配置好的数据库。
3、 点击上面一行第一个的连接,在出现的页面中勾选MySQL方框,选择MySQL图标。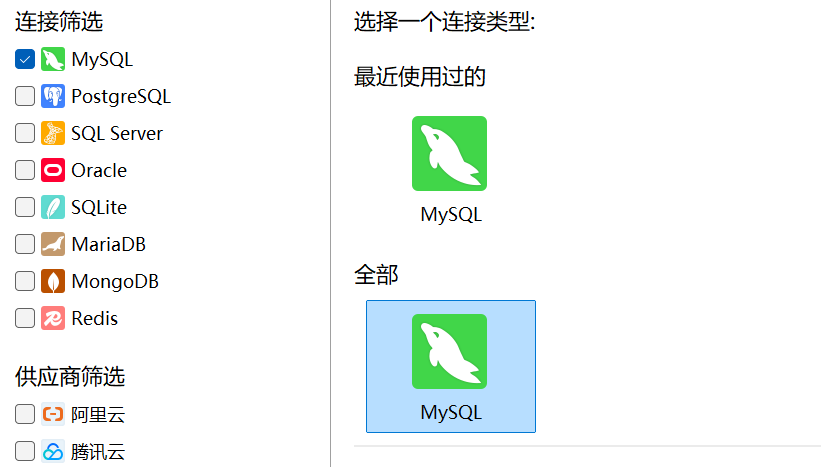
4、 连接名称随你,哪个密码就是你最开始配置MySQL的root的密码。
5、 点击最下面的测试连接,没有红色报错就是测试成功。
数据库的操作
创建数据库
在Navicat里创建第一个数据库,首先新建查询,点击连接旁边的新建查询,下面会出现无标题-查询。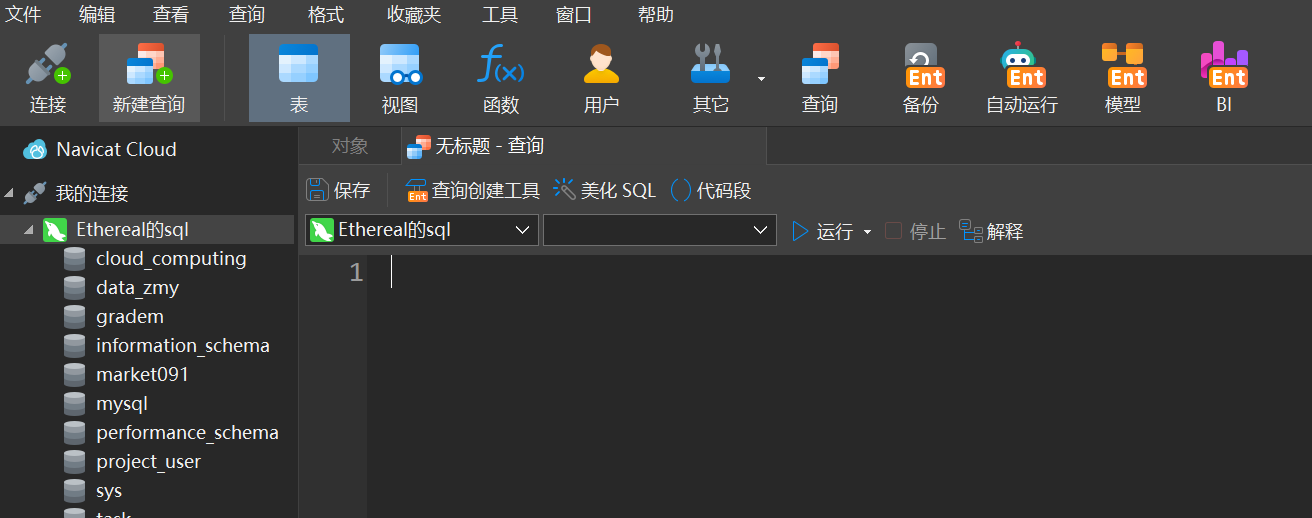
输入:
1 | create database <数据库名字>; |
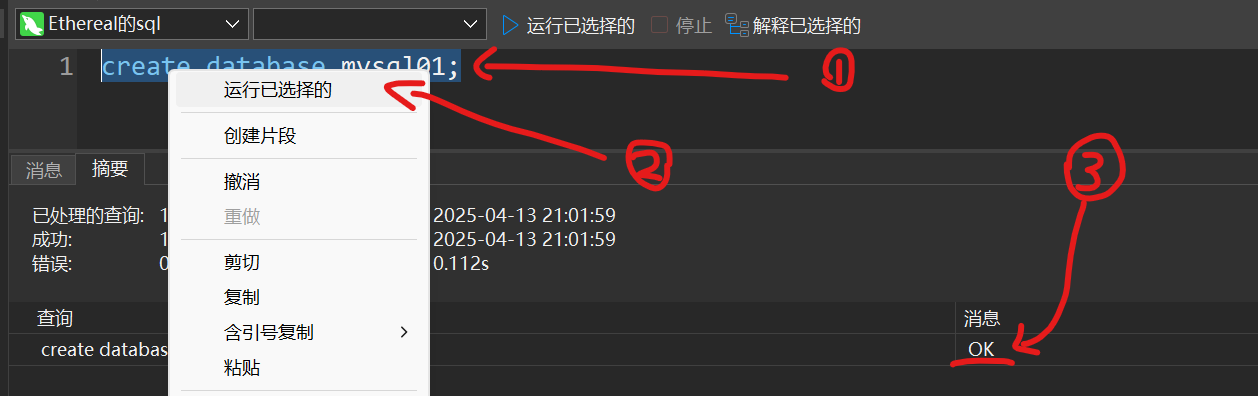
出现ok就表示创建名为mysql01的数据库成功,在左边的一列也就是xxx(你自己的命名)的sql右键点击最下面的刷新,此时会出现刚刚建好的数据库
使用数据库
用来切换数据库
1 | use <数据库>; |
删除数据库
1 | DROP DATABASE <数据库>; |
查看数据库下所有的表
1 | show TABLES; |
先选择要查询的数据库,然后再执行命令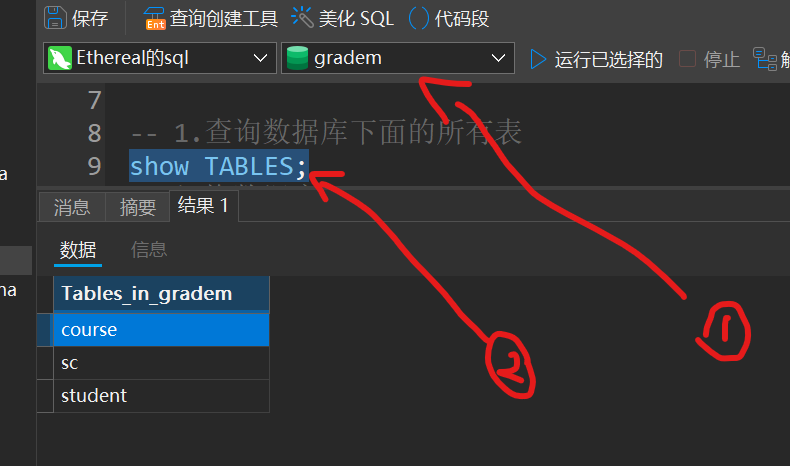
数据表的操作
表的创建
1 | CREATE TABLE <表名> ( |
实例:
创建一个用户表 users
1 | CREATE TABLE users ( |
解析:
- id: 用户 id,整数类型,自增长,作为主键。
- username: 用户名,变长字符串,不允许为空。
- email: 用户邮箱,变长字符串,不允许为空。
- birthdate: 用户的生日,日期类型。
- is_active: 用户是否已经激活,布尔类型,默认值为 true。
表的删除
1 | drop table <表名>; |
修改表名
1 | alter table <旧表名> rename to <新表名>; |
表里添加/修改/删除字段(属性)
添加字段(属性)
1 | alter table <表名> add <字段> <数据类型>; |
修改数据类型
1 | alter table <表名> modify <要修改的字段> <新的数据类型>; |
删除字段
1 | alter table <表名> drop <要删的字段>; |
复制表
1 | create table <新表> select * from <源表>; |
DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
添加数据
给指定字段添加数据
1 | insert into employee(字段1,字段2,字段3,字段4,字段5,字段6) |
直接给表所有字段添加数据(前提是你非常熟悉这张表的字段)
1 | insert into employee values(值1,值2,值3,值4); |
批量加数据·方式1
1 | insert into employee(字段1,字段2,字段3,字段4) |
批量加数据·方式2
1 | insert into employee values |
修改数据
1 | update <表名> set <字段名1> = 值1, <字段名2> = 值2,... [where 条件]; |
可能这样说比较抽象,最好在自己电脑里试一下。下面举例
eg.
在employee表里修改id为1的数据, 将name修改为小昭, gender修改为 女
1 | update employee set name = '小昭' , gender = '女' where id = 1; |
注意事项:
修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据
删除数据
1 | delete from <表名> [where 条件]; |
在employee表里删除gender为女的员工
1 | delete from employee where gender = '女'; |
DQL
DQL英文全称是Data Query Language(数据查询语言),数据查询语言,用来查询数据库中表的记录。(其实这个用的是最多的🥸🤔)
查询关键字: select
基本语法
DQL查询语句,语法结构如下:
1 | SELECT |
把上面分分类可以分为以下几个部分
- 基本查询(不带任何条件)
- 条件查询(where)
- 聚合函数(sum(),mix(),count(),min()…)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
基本查询
在基本查询的DQL语句中,不带任何的查询条件,查询的语法如下:
1 | select * from <表名>; |
1 | select <字段1>,<字段2>... from <表名>; |
注意:可在select后面加上’distinct’用于去除重复记录的
条件查询
常用的比较运算符如下:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN … AND … | 在某个范围之内(含最小,最大值) |
| IN(…) | 在in之后的列表中的值,多选一 |
| LIKE() | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| IS NULL | 是NULL |
案例:查询年龄等于 88 的员工
1 | select * from emp where age = 88; |
案例:查询没有身份证号的员工信息
1 | select * from emp where idcard is null; |
案例:查询年龄在15岁(包含) 到 20岁(包含)之间的员工信息 –> 有三种方法
1 | select * from emp where age > = 15 && age < = 20; |
案例:查询姓名为两个字的员工信息
1 | select * from emp where name like '__'; # 这里是两个下划线 |
案例:查询身份证号最后一位是X的员工信息
这里我推荐第一个用法,第二个用法太麻烦了。
1 | select * from emp where idcard like '%X'; |
聚合函数
将一列数据作为一个整体,进行纵向计算 。
以下是常见的聚合函数
| 函数 | 功能 |
|---|---|
| count | 统计函数 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
1 | select 聚合函数(字段列表) from <表名>; |
案例:统计该企业员工数量
1 | select count(*) from emp; -- 统计的是总记录数 |
案例:统计该企业员工的平均年龄
1 | select avg(age) from emp; |
案例: 统计该企业员工的最大年龄
1 | select max(age) from emp; |
案例:统计西安地区员工的年龄之和
1 | select sum(age) from emp where workaddress = '西安'; |
分组查询
1 | select <字段列表> from <表名> where <条件> group by <分组字段名> having <分组后过滤条件>; |
案例:根据性别分组 , 统计男性员工 和 女性员工的数量
1 | select gender, count(*) from emp group by gender; |
案例:根据性别分组 , 统计男性员工 和 女性员工的平均年龄
1 | select gender,avg(age) from emp group by gender; |
案例:查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址
1 | select workaddress,count(*) as address_count, from emp where age < 45 group by workaddress having address_count >= 3; |
排序查询
其实就是升序排序和降序排序。
1 | select <字段列表> from <表名> order <字段1> 排序方式1,<字段2> 排序方式2; |
升序:ASC
降序:DESC
案例:根据年龄对公司的员工进行升序排序
1 | select * from emp order by age asc; |
注意: 如果是升序,可以省略掉,因为这是默认值。
分页查询
常见的一个功能,我们在网站中看到的各种各样的分页条,后台都需要借助于数据库的分页操作。
1 | select <列表字段> from <表名> limit 起始索引, 查询记录数 ; |
注意事项:
• 起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
• 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
案例:查询第2页员工数据, 每页展示10条记录
利用公式:(查询页码 - 1)* 每页显示记录数。从案例中我们得知要查第2页,每页10条记录。所以就是(2-1)*10 等于 10。
1 | select * from <> limit 10,10; |
DCL
DCL语句用得不多,这里就稍微记录它的语法吧!
管理用户
查询用户
1 | select * from mysql.user; |
创建用户
1 | CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码'; |
修改用户密码
1 | ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码'; |
删除用户
1 | DROP USER '用户名'@'主机名'; |
授予权限
1 | GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名'; |
撤销权限
1 | REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名'; |
函数
函数 是指一段可以直接被另一段程序调用的程序或代码。它和聚集函数是不同的概念。
MySQL中的函数主要分为以下四类: 字符串函数、数值函数、日期函数、流程函数。
字符串函数
演示如下:
concat : 字符串拼接
1 | select concat('Hello' , ' MySQL'); |

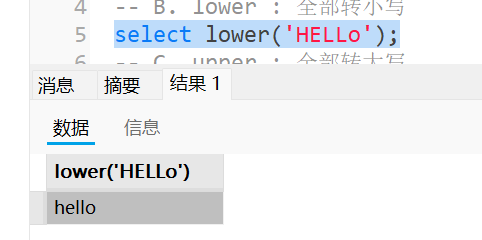
lower : 全部转小写
1 | select lower('HELLo'); |
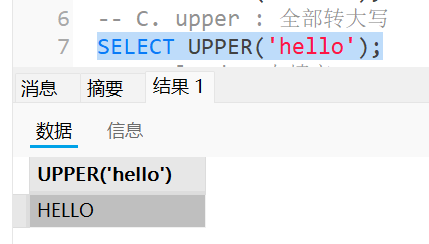
upper : 全部转大写
1 | select upper('Hello'); |
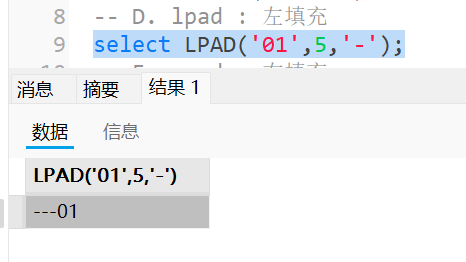
lpad : 左填充
1 | select LPAD('01',5,'-'); |
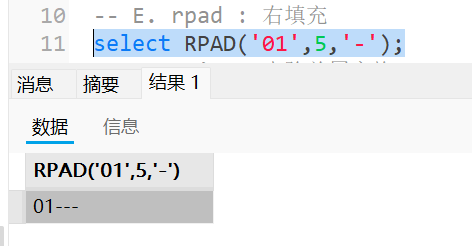
rpad : 右填充
1 | select rpad('01', 5, '-'); |
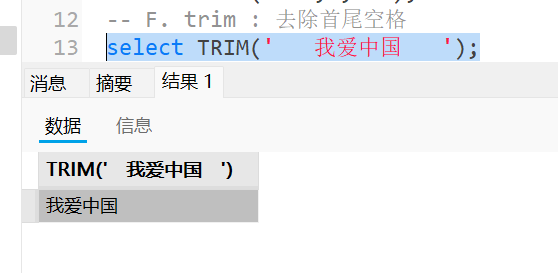
trim : 去除空格
1 | select TRIM(' 我爱中国 '); |
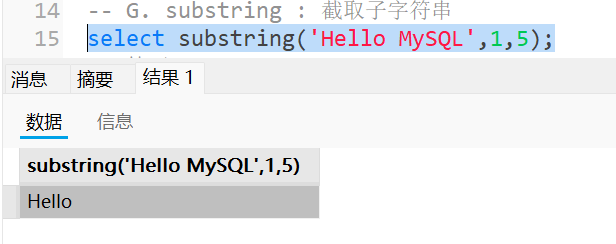
substring : 截取子字符串
1
select substring('Hello MySQL',1,5);
数值函数
日期函数
流程函数

未完待续
 微信
微信 支付宝
支付宝




