
前言
学会用 Python 爬虫的前提是要掌握 Python 的基本语法、数据类型、流程控制等。理解函数、模块和异常处理。站长最近也在学习爬虫,是初学者。希望这篇文章可以帮到你。
开始
在我们对某个网站进行爬取之前,需要对其数据进行分析,了解应该如何请求以及获取的数据是什么样的。因此,我们需要进行数据抓包。以下是具体步骤:
- 打开 Chrome 浏览器:注意不要使用国产浏览器,这里就不必多说了,懂得都懂。
- 访问网站:输入我们都知道的一个网站 www.baidu.com。
- 打开开发者工具:按下
F12键,跳出开发者工具页面。 - 选择“网络”标签:点击“网络”标签或 Network 标签,然后刷新页面,就可以看到很多的请求。
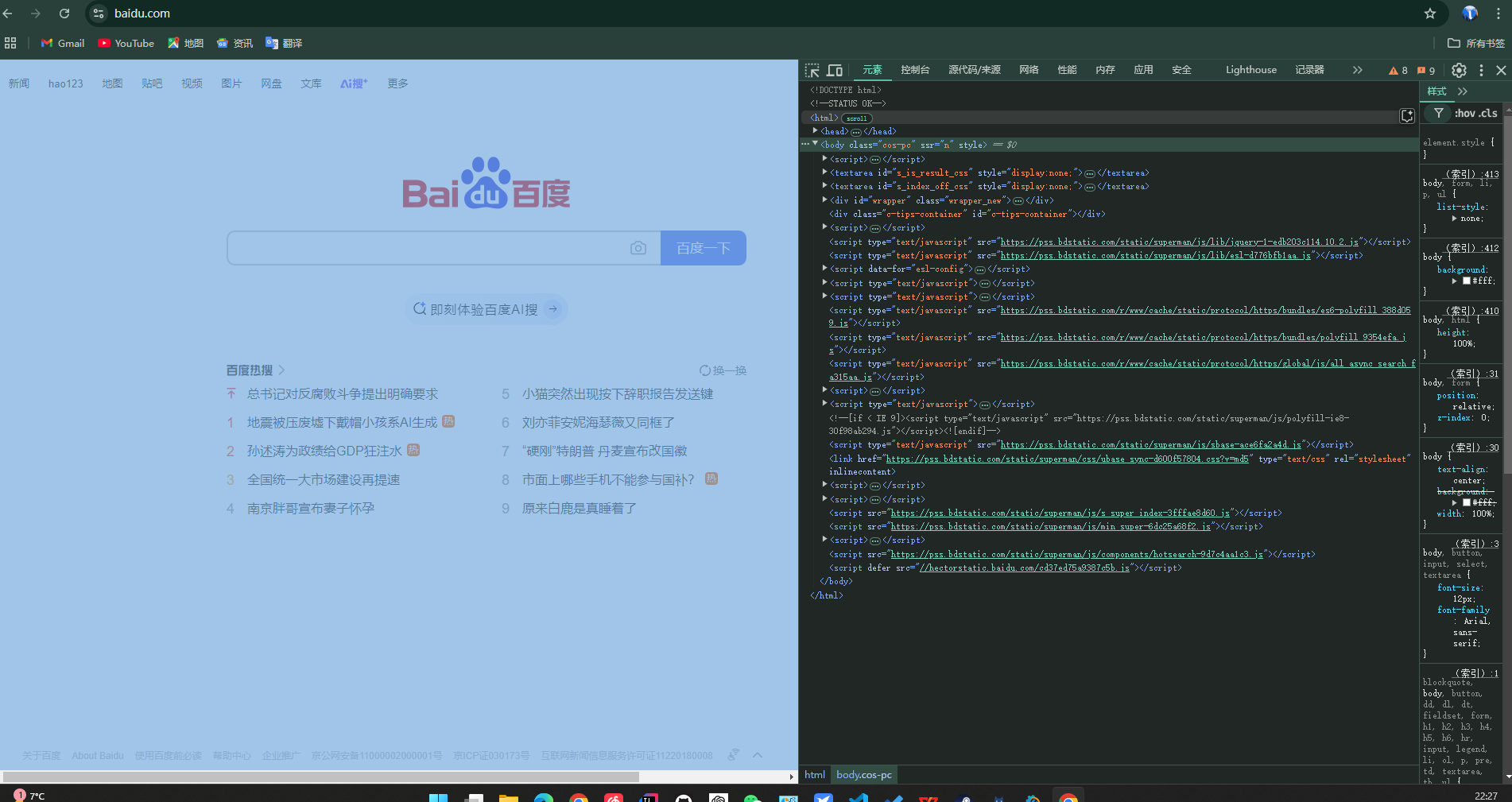
HTTP 请求
HTTP 的请求方式有好几种,不过最常见的是 GET 和 POST 请求。随便搜索一个词,然后我们就会发现很多请求,这些都是 GET 请求。随便点一个请求就可以看到我们的请求 URL 地址:https://www.baidu.com/s?ie=utf-8&f=3&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E8%8A%99%E5%AE%81%E5%A8%9C%E5%9B%BE%E7%89%87%E5%A3%81%E7%BA%B8&fenlei=256&rsv_pq=0x9a5a9b3c00922a0f&rsv_t=3b4ah4PLO6Yypwe5gUQqOvMWOR%2Bo1EUivIsHINEIcBDqLaDWQ%2BnkKNzRnGxD&rqlang=en&rsv_dl=ts_2&rsv_enter=1&rsv_sug3=18&rsv_sug1=22&rsv_sug7=101&rsv_sug2=1&rsv_btype=i&prefixsug=%25E8%258A%2599%25E5%25AE%2581%25E5%25A8%259C&rsp=2&
在 ? 后面的这些就是 GET 请求的参数,这些参数以键值对的形式实现,比如:wd=%E8%8A%99%E5%AE%81%E5%A8%9C%E5%9B%BE%E7%89%87%E5%A3%81%E7%BA%B8
就是在告诉百度,我们要查询的是芙宁娜图片壁纸相关的东西,我们在百度搜索”原神”就是https://www.baidu.com/s?wd=愿神 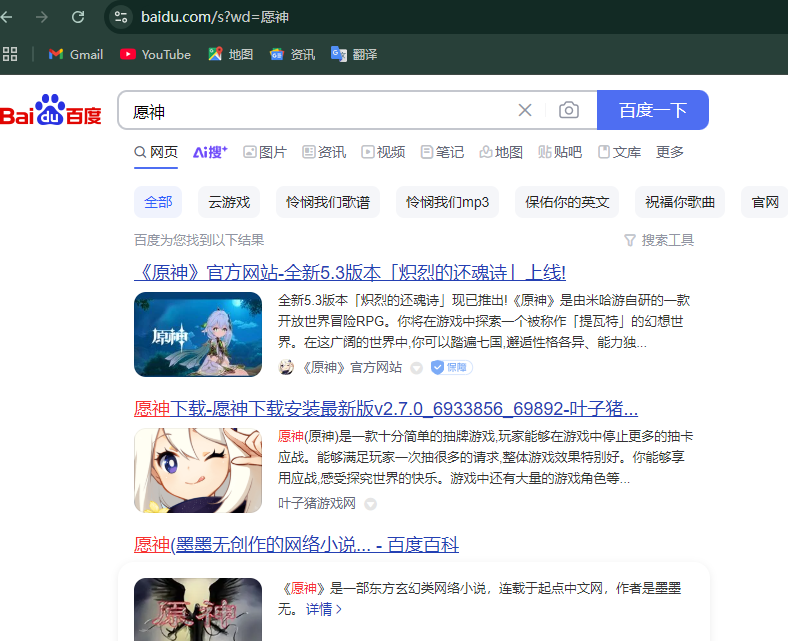
总结
通过这篇文章,我们了解了如何使用 Chrome 浏览器的开发者工具进行数据抓包,并分析了 GET 请求的参数。希望这篇文章对你学习 Python 爬虫有所帮助。
如果你有任何问题或建议,欢迎在评论区留言。
 微信
微信 支付宝
支付宝




